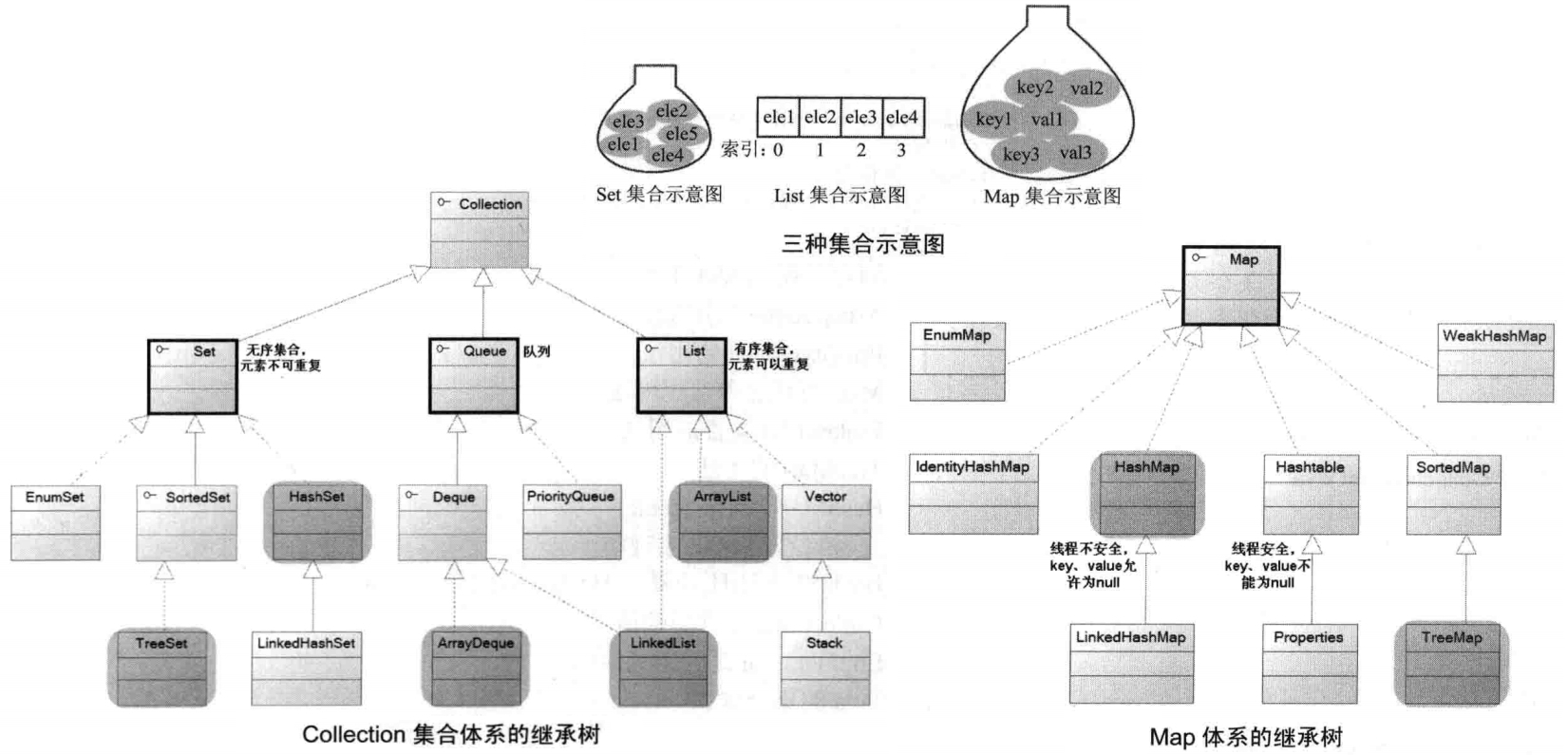
- jdk1.2 开始出现,相关的接口和类都在 java.util 包中,保存的是对象的引用
- jdk1.2 以前“古老”的集合类:Vector、Hashtable(都是同步的)
# Collection 和 Iterator 接口
# Collection 接口操作集合元素的方法
Iterable 的子接口
增加
boolean add(Object o):向集合里添加一个元素,如果集合对象被添加操作改变了,则返回 trueboolean addAll(Collection c):把集合 c 里的所有元素添加到指定集合里,如果集合对象被添加操作改变了,则返回 true
删除
boolean remove(Object o):删除集合中第一个符合条件的指定元素 o,返回 trueboolean removeAll(Collection c):从该集合中删除集合 c 里包含的所有元素,如果删除了一个或一个以上的元素,该方法将返回 trueboolean retainAll(Collection c):使该集合中仅保留集合 c 里包含的元素(求两个集合的交集),如果该操作改变了调用该方法的集合,则该方法返回 truevoid clear():清除集合里的所有元素,将集合长度变为 0
查询
boolean contains(Object o):判断集合里是否包含指定元素 oboolean containsAll(Collection c):判断集合里是否包含集合 c 里的所有元素boolean isEmpty():判断集合是否为空,当集合长度为 0 时返回 true,否则返回 falseint size():返回集合里元素的个数
其它操作
Iterator<E> iterator():获取一个 Iterator 对象(迭代器)Object[] toArray():把集合转换成一个数组,所有的集合元素变成对应的数组元素(转换成 Object 数组时,没有必要使用toArray[new Object[0]],可以直接使用toArray())T[] toArray(T[] a):返回一个包含此集合中所有元素的数组(返回数组的运行时类型是指定数组的类型)。如果指定的数组 a 能容纳该集合,则 a 将在其中返回;否则,将分配一个具有指定数组的运行时类型和此集合大小的新数组(集合转换为类型 T 数组时,尽量传入空数组 T[0])
默认方法
Stream<E> stream()Stream<E> parallelStream()boolean removeIf(Predicate<E> filter):删除满足给定谓词的此集合的所有元素void forEach(Consumer<? super T> action):对 Iterable 的每个元素执行给定的操作
# 使用 Iterator 遍历集合元素
Iterator 接口用于遍历(即迭代访问)Collection 集合中的元素
通过把集合元素的值传给了迭代变量
在创建 Iterator 迭代器之后,除非通过迭代器自身的 remove() 方法对 Collection 集合里的元素进行修改,否则在对 Collection 集合进行添加或删除元素后再使用迭代器进行迭代访问时,迭代器会抛出 ConcurrentModificationException(由 checkForComodification() 抛出,原因为
modCount != expectedModCount,modCount 表示集合对象结构性修改的次数,expectedModCount 是迭代器对象中的一个成员变量)实例方法
boolean hasNext():如果集合里仍有元素可以迭代,则返回 trueObject next():返回集合里的下一个元素void remove():删除集合里上一次 next 方法返回的元素
快速失败(fail-fast)
- 一种迭代器策略
- 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改,modCount != expectedmodCount),则会抛出 ConcurrentModificationException
- java.util 包下的集合类都是快速失败的,不能在多线程下发生并发修改
# 使用 foreach 循环遍历集合元素
- 与使用 Iterator 接口迭代访问集合元素类似,foreach 循环中的迭代变量也不是集合元素本身,系统只是依次把集合元素的值赋给迭代变量,所以在遍历时不能对 Collection 集合进行添加或删除元素,否则会抛出 ConcurrentModificationException(可以使用特殊的集合 CopyOnWriteArrayList、CopyOnWriteSet、ConcurrentHashMap)
# 使用 for 循环遍历集合元素
在遍历时可以对 Collection 集合里的元素进行修改
当删除多个元素时,应从后往前遍历,如果从前往后遍历,在删除元素后需要调整迭代变量
// 删除元素后索引会左移,所以在删除元素后需要调整迭代变量 for (int i = 0; i < list.size(); i++) { if (list.get(i) == 3) { list.remove(i--); } } for (int i = list.size() - 1; i >= 0; i--) { if (list.get(i) == 3) { list.remove(i); } }1
2
3
4
5
6
7
8
9
10
11
12
# List 集合
- 记录元素的添加顺序,允许元素重复的集合,列表
- 默认按元素的添加顺序设置元素的索引
# List 接口
List 判断两个对象相等的标准:两个对象相等通过 equals() 方法比较返回 true
增加
void add(int index, Object element):将元素 element 插入到 List 集合的 index 处,索引范围 [0, size)boolean addAll(int index, Collection c):将集合 c 所包含的所有元素都插入到 List 集合的 index 处
删除
Object remove(int index):删除并返回 index 索引处的元素
修改
Object set(int index, Object element):将 index 索引处的元素替换成 element 对象,返回被替换的旧元素
查询
Object get(int index):返回集合 index 索引处的元素int indexOf(Object o):返回对象 o 在 List 集合中第一次出现的位置索引int lastIndexOf(Object o):返回对象 o 在 List 集合中最后一次出现的位置索引
其它
List subList(int fromlndex, int tolndex):返回从索引 fromlndex(包含)到索引 tolndex(不包含)处所有集合元素组成的子集合,返回的列表由此列表支持,因此返回列表中的非结构性更改将反映在此列表中,反之亦然(对于子列表的所有操作最终会反映到原列表上;对父集合元素的增加或删除,均会导致子列表的遍历、增加、删除产生 ConcurrentModificationException 异常)ListIterator<E> listIterator(int index):返回一个 ListIterator 对象(双向的迭代器),从列表的指定位置开始
默认方法
void replaceAll(UnaryOperator<E> operator):对列表中的每一个元素执行特定的操作,并用处理的结果替换该元素void sort(Comparator<E> c):使用提供的 Comparator 来比较元素排序该列表
常用构造器
ArrayList():构造一个初始容量为 10 的空列表,从 Java 8 开始初始化时使用了一个空数组 Object[],等到需要存储数据时才分配空间(延迟初始化)ArrayList(Collection<? extends E> c):构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的HashSet():构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75HashSet(Collection<? extends E> c):构造一个包含指定 collection 中的元素的新 set
# ListIterator 接口
List 还可以使用普通的 for 循环、listIterator() 方法来遍历集合元素
ListIterator 接口继承了 Iterator 接口,额外的方法:
boolean hasPrevious():判断该迭代器关联的集合是否还有上一个元素Object previous():返回该迭代器的上一个元素void add(Object o):在指定位置插入一个元素void set(E e):用指定元素替换 next 或 previous 返回的最后一个元素
ArrayList<String> ls = new ArrayList<>();
// 普通 for 循环
for (int i = 0; i < ls.size(); i++) {
System.out.println(ls.get(i));
}
// 增强 for 循环(底层采用 Iterator 迭代器)
for (String str : ls) {
System.out.println(str);
}
// for 循环迭代器
for (Iterator<String> it = ls.iterator(); it.hasNext();) {
System.out.println(it.next());
}
// while 循环迭代器
Iterator<String> it = ls.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
// 自定义类中重写 equals() 方法
public class Point {
private int x;
private int y;
// 此处省略 x 和 y 的 setter 和 getter 方法
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
public boolean equals(Object obj) {
// 是否同一对象
if (this == obj) return true;
// 是否为空
if (obj == null) return false;
// 类型是否相同
if (getClass() != obj.getClass()) return false;
Point other = (Point) obj; // 强转
if (x != other.x) return false;
if (y != other.y) return false;
return true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# ArrayList 和 Vector 实现类
- 基于 Object[] 的 List 接口的实现类,查询元素较快
- RandomAccess (标识接口,支持快速随机访问)的实现类
- 使用 initialCapacity 参数来设置该数组的长度,并且会自动增加(默认为 10)
- ArrayList 以 1.5 倍的方式扩容,Vector 以 2 倍的方式扩容
- Vector 的子类 Stack(用于模拟栈)中的额外方法(数组的最后一个元素位置作为栈顶):
void push(Object item)、Object pop()、Object peek()
# LinkedList 实现类
- 基于双向链表的 List、Deque 接口的实现类,
添加删除元素比较快(需要先通过循环获取到对应节点的 Node) - 双向链表、单向队列、双向队列、栈(链表的第一个节点位置作为栈顶)
在各种常用场景下,LinkedList 几乎都不能在性能上胜出 ArrayList
# Queue 集合
队列,“先进先出”(FIFO)的容器
Queue 接口中的方法
void add(Objecte):将指定元素加入此队列的尾部Object element():获取队列头部的元素,但是不删除该元素boolean offer(Objecte):将指定元素加入此队列的尾部。当使用有容量限制的队列时,此方法通常比add(Object e)方法更好Object peek():获取队列头部的元素,但是不删除该元素。如果队列为空,则返回 nullObject poll():获取队列头部的元素,并删除该元素。如果队列为空,则返回 nullObject remove():获取队列头部的元素,并删除该元素
# Deque 子接口
- 双端队列,支持在两端插入和移除元素
- 队列,将元素添加到双端队列的末尾,从双端队列的开头移除元素
- 栈,双端队列的开头作为栈顶
- 实现类:ArrayDeque、LinkedList
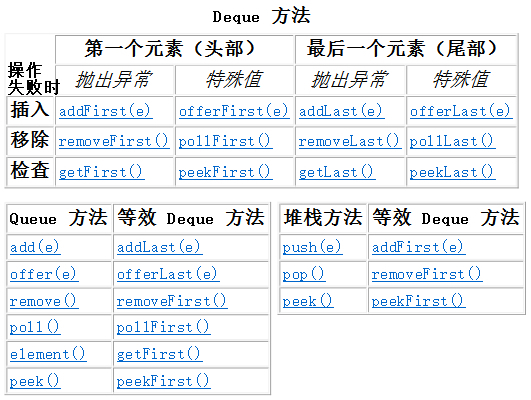
Iterator descendingIterator():返回该双端队列对应的迭代器,该迭代器将以逆向顺序来迭代队列中的元素
# PriorityQueue 优先队列
- 基于堆实现无界优先级队列
- 可在构造器中自定义优先级别
PriorityQueue(Comparator<? super E> comparator) - 队列的头是按指定排序方式确定的最小元素
- 默认小顶堆:
new PriorityQueue<>()或new PriorityQueue<>((a, b) -> a - b)(升序) - 大顶堆:
new PriorityQueue<>(Comparator.reverseOrder())或new PriorityQueue<>((a, b) -> b - a)(降序) - 实例方法
boolean add(E e)、boolean offer(E e):将指定的元素插入此优先级队列E peek():获取但不移除此队列的头;如果此队列为空,则返回 nullE remove()、E poll():获取并移除此队列的头,队列为空时,remove() 抛出异常,poll() 返回 null
# Set 集合
- 不记录元素的添加顺序,不允许元素重复的集合
- 尽量不要修改 Set 集合元素中判断两个元素相等的方法用到的实例变量,否则将会导致 Set 无法正确操作这些集合元素;Set 存储的对象必须覆写 hashCode 和 equals
# HashSet 类
- 内部采用 HashMap 实现(将该元素作为 key,
new Object()作为 value 放入 HashMap 中) - 最多包含一个 null 元素,其索引为 0
- HashSet 集合判断两个元素相等的标准:两个对象的 hashCode() 方法返回值相等,并且两个对象通过 equals() 方法比较也相等
- 如果需要把某个类的对象保存到 HashSet 集合中,重写这个类的 equals()、hashCode() 方法时,应保证两个对象通过 equals() 方法比较返回 true 时,它们的 hashCode() 方法返回值也相等
- 当程序把可变对象添加到 HashSet 中之后,尽量不要去修改该集合元素中参与计算 hashCode()、equals() 的实例变量,否则将会导致 HashSet 无法正确操作这些集合元素
# LinkedHashSet 类
- HashSet 的子类
- 根据元素的 hashCode 值来决定元素的存储位置,同时使用链表维护元素添加顺序
# TreeSet 类
- NavigableSet 接口(SortedSet 的子接口)的实现类,元素处于排序状态
- 内部采用 TreeMap 实现(将该元素作为 key,
new Object()作为 value 放入 TreeMap 中) - TreeSet 支持两种排序方法:自然排序(默认)和定制排序
- TreeSet 集合判断两个元素相等的标准:元素的
compareTo(Object obj)方法或 Comparator 对象的compare(T o1, T o2)方法的返回值为 0 - 只能添加同一种类型的对象(需要比较大小),否则会引发 ClassCastException 异常
- 当需要把一个对象放入 TreeSet 中,重写该对象对应类的 equals() 方法时,应保证该方法与
compareTo(Object obj)方法有一致的结果 - 额外的方法
- 查询
Object first():返回集合中的第一个元素Object last():返回集合中的最后一个元素Object lower(Object e):返回集合中位于指定元素之前的元素(即小于指定元素的最大元素,参考元素不需要是 TreeSet 集合里的元素)Object higher (Object e):返回集合中位于指定元素之后的元素(即大于指定元素的最小元素,参考元素不需要是 TreeSet 集合里的元素)
- 其它
SortedSet subSet(Object fromElement, Object toElement):返回此 Set 的子集合(部分视图),范围从 froraElement(包含)到 toElement (不包含),返回的 Set 受此 Set 支持,所以在返回 Set 中的更改将反映在此 Set 中,反之亦然SortedSet headSet(Object toElement):返回此 Set 的子集(部分视图),由小于 toElement 的元素组成,返回的 Set 受此 Set 支持,所以在返回 Set 中的更改将反映在此 Set 中,反之亦然SortedSet tailSet(Object fromElement):返回此 Set 的子集(部分视图),由大于或等于 fromElement 的元素组成,返回的 Set 受此 Set 支持,所以在返回 Set 中的更改将反映在此 Set 中,反之亦然Comparator comparator():如果 TreeSet 采用了定制排序,则该方法返回定制排序所使用的 Comparator;如果 TreeSet 采用了自然排序,则返回 null
- 查询
# 自然排序
- 要求添加的对象的类必须实现 Comparable 接口
- 调用集合元素的
compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列 - java.lang.Comparable<T> 接口:
int compareTo(T o):如果该对象小于、等于或大于指定对象,则分别返回负整数、0 或正整数

# 定制排序
在创建 TreeSet 集合对象时,提供一个 Comparator 对象(比较器)与该 TreeSet 集合关联,由该 Comparator 对象负责集合元素的排序逻辑
new TreeSet(Comparator c)java.util.Comparator<T> 接口:
int compare(T o1, T o2):如果第一个参数小于、等于或大于第二个参数,则分别返回负整数、0 或正整数
# Map 集合
- 用于保存具有映射关系的数据,元素是 key-value 对(Entry),key 不允许重复
- 本质 Map.Entry<K,V>[]
- 尽量不要修改作为 key 的可变对象的关键实例变量(避免后续无法正确地找到该 key 对应的 value);作为 key 的自定义对象必须覆写 hashCode 和 equals
- 增加 / 修改
Object put(Object key, Object value):添加一个 key-value 对,如果当前 Map 中已有一个与该 key 相等的 key-value 对,则新的 key-value 对会覆盖原来的 key-value 对,返回被覆盖的 value,否则返回 nullvoid putAll(Map m):将指定 Map 中的 key-value 对复制到本 Map 中
- 删除
Object remove(Object key):删除指定 key 所对应的 key-value 对,返回被删除 key 所关联的 value,如果该 key 不存在,则返回 nullboolean remove(Object key, Object value):删除指定 key、value 所对应的 key-value 对(Java 8 新增)void clear():删除该 Map 对象中的所有 key-value 对
- 查询
Object get(Object key):返回指定 key 所对应的 value;如果此 Map 中不包含该 key,则返回 nullboolean containsKey(Object key):查询 Map 中是否包含指定的 key,如果包含则返回 trueboolean containsValue(Object value):查询 Map 中是否包含一个或多个 value,如果包含则返回trueboolean isEmpty():查询该 Map 是否为空(即不包含任何 key-value 对),如果为空则返回 trueint size():查询该 Map 里的 key-value 对的个数
- 其它
Set<K> keySet():返回该 Map 中所有 key 组成的 Set 集合(相应实现类中的内部类,不支持 add 或 addAll 操作)Collection<V> values():返回该 Map 里所有 value 组成的 Collection(相应实现类中的内部类,不支持 add 或 addAll 操作)Set<Map.Entry<K, V>> entrySet():返回 Map 中包含的 key-value 对所组成的 Set 集合,每个集合元素都是 Map.Entry 对象(不支持 add 或 addAll 操作)
- 默认方法
void forEach(BiConsumer<K, V> action):对此映射中的每个条目执行给定的操作V computeIfPresent(K key, BiFunction<K, V, V> remappingFunction)V computeIfAbsent(K key, Function<K, V> mappingFunction):如果 key 不存在或者对应的值是 null,则调用 mappingFunction 来产生一个值,然后将其放入 Map(原子操作 CAS),再返回这个值;否则返回 Map 已存在的对应的值V putIfAbsent(K key, V value):如果 key 不存在或者对应的值是 null,则将 value 设置进去(原子操作 CAS),然后返回 null;否则返回 Map 中已存在的对应的值V getOrDefault(Object key, V defaultValue):如果 key 不存在或者对应的值是 null,则返回 defaultValueboolean remove(Object key, Object value):仅当指定的 key 当前映射到指定的值时删除该条目boolean replace(K key, V oldValue, V newValue):仅当当前映射到指定的值时,才替换指定键的条目V merge(K key, V value, BiFunction<V, V, V> remappingFunction):如果指定的 key 尚未与值相关联或与 null 相关联,则将其与给定的非空 value 相关联,否则将关联值替换为给定重映射函数remappingFunction.apply(oldValue, value)的结果,如果给定重映射函数的结果为 null 则删除
- 常用构造器
HashMap():构造一个具有默认初始容量(16)和默认加载因子(0.75)的空 HashMapHashMap(Map<? extends K,? extends V> m):构造一个映射关系与指定 Map 相同的新 HashMap
# 内部类 Map.Entry<K, V>
内部类 Map.Entry<K, V> ,封装了一个 key-value 对
静态方法
Comparator<Map.Entry<K, V>> comparingByKey():返回一个比较器,按自然顺序比较 Map.Entry 中的 keyComparator<Map.Entry<K, V>> comparingByKey(Comparator<K> cmp):返回一个比较器,使用给定的 Comparator 比较 Map.Entry 中的 keyComparator<Map.Entry<K, V>> comparingByValue():返回一个比较器,按自然顺序比较 Map.Entry 中的 valueComparator<Map.Entry<K, V>> comparingByValue(Comparator<V> cmp):返回一个比较器,使用给定的 Comparator 比较 Map.Entry 中的 value
实例方法
Object getKey():返回该 Entry 里包含的 key 值Object getValue():返回该 Entry 里包含的 value 值Object setValue(V value):设置该 Entry 里包含的 value 值,并返回新设置的 value 值
// 通过 keySet
Set<String> keySet = map.keySet();
for (String key : keySet) {
System.out.println(key + "<=>"+map.get(key));
}
// (推荐)通过 entrySet
Set<Entry<String, Integer>> entrySet = map.entrySet();
for (Map.Entry<String, Integer> entry : entrySet) {
System.out.println(entry.getKey() + "<=>" + entry.getValue());
}
// (推荐)通过 Map.forEach
properties.forEach((key, value) -> {
System.out.println(key + "<=>" + value);
});
List<Map<String, Object>> list = new ArrayList<>();
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# HashMap 和 Hashtable 实现类
HashMap 可以使用 null 作为 key 或 value,Hashtable 不允许
无序,底层采用数组和链表(或红黑树)来存储 key-value 对
底层数组的每个元素(通常称为"桶")保存的都是一个指向 Node<K,V> 对象的引用
保证 key 唯一的原理和 HashSet 一样:首先 hash(key) 得到 key 的 hashcode,HashMap 根据获得的 hashcode 找到要插入的位置所在的链,在这个链里面放的都是 hashcode 相同的 Entry 键值对,在找到这个链之后,会通过 equals() 方法判断是否已经存在要插入的键值对,而这个 equals 比较的其实就是 key
默认的初始容量(capacity)为 16
hash 冲突:如果两个对象的 hashCode() 方法返回的 hashCode 值相同,但通过 equals() 方法比较返回 false
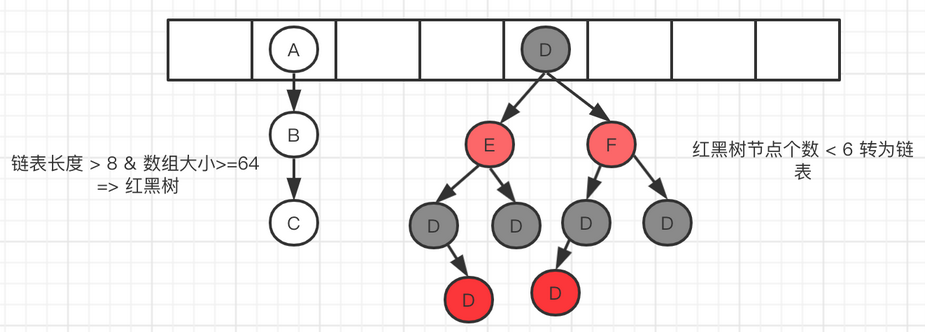
采用链地址法解决 hash 冲突: HashSet 会发生 hash 冲突的位置(桶 bucket)用链表来保存这些对象(jdk1.8 中,如果某位置碰撞的数量超过 8 且总容量大于 64 时就会将链表置为红黑树)(在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显)(当碰撞的数量小于 6 转换为链表)
HashMap 的哈希函数设计:
hash = (h = key.hashCode()) ^ (h >>> 16)(hashCode 右移 16 位再进行异或操作)目的:低位掩码(利用高位码去替换低位码);扰动函数,减少 hash 冲突;
当通过构造器指定集合初始容量时,实际初始化时的容量为大于指定参数且最近的 2 的整数次方的数(
tableSizeFor()方法),即 2->2、3->4、7->8、13->16原因:当 n 等于 2 的整数次方时,满足 (n - 1) & hash = hash % n
- 计算 key 位置时,& 按位与运算速度比 % 取模运算快
- hash 冲突少:2 的整数次方的二进制是最高位 1 其它低位是 0,减 1 后可以得到 1111 这样都是 1 的二进制,只有全是 1,进行按位与才是最均匀的,因为 1 & 任何数都等于任何数本身
建议
initialCapacity = (int) (expectedSize / 0.75F + 1)(com.google.common.collect.Maps#capacity 或 newHashMapWithExpectedSize)或initialCapacity = (int) Math.ceil(expectedSize / 0.75F)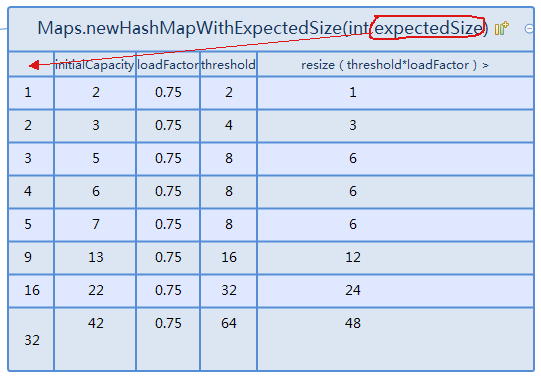
装载因子(load factor)等于“size/capacity’’,默认的装载因子阈值为 0.75,表明当该 hash 表的 3/4 已经被填满,再添加 key-value 对时,hash 表会发生 rehashing,即 hash 表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内
装载因子阈值需要选择得当:如果太大,会导致冲突过多,增加查询数据的时间开销;如果太小,会导致内存浪费严重
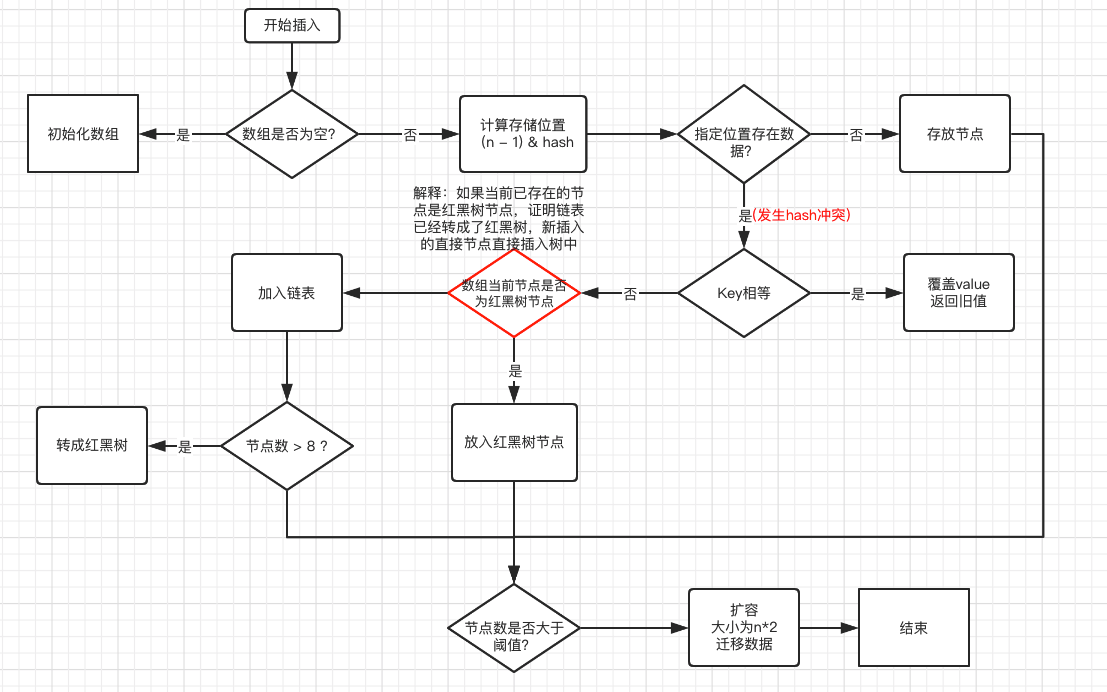
- jdk1.8 的优化:
- 数组+链表 改成了 数组+链表或红黑树
- 链表的插入方式从头插法改成了尾插法:插入时,如果数组位置上已经有元素,1.7 将新元素放到数组中,原始节点作为新节点的后继节点,1.8 遍历链表,将元素放置到链表的最后(1.7 头插法扩容时,头插法会使链表发生反转,多线程环境下会产生环)
- 扩容时,1.7 需要对原数组中的元素进行重新 hash 定位在新数组的位置,1.8 采用更简单的判断逻辑,当
(e.hash & oldCap) == 0时,位置不变,否则移动到当前 hash 槽位 + oldCap 的位置 - 在插入时,1.7 先判断是否需要扩容,再插入,1.8 先进行插入,插入完成再判断是否需要扩容
# LinkedHashMap 类
HashMap 的子类,使用双向链表来维护 key-value 对的插入顺序或访问顺序
LinkedHashMap 的 Entry 节点,extends HashMap.Node,额外添加了两个引用:before、after,通过这两个引用,所有存储在 Map 中的 Entry 节点被串联成一个双向链表
可用来构建 LRU 缓存,淘汰最长时间未被使用的数据
// accessOrder 设置为 true,访问顺序,即 LRU 模式 LinkedHashMap lruCache = new LinkedHashMap<K, V>(16, 0.75F, true) { // 允许 LinkedHashMap 在插入新元素时自动淘汰旧元素,默认始终返回 false protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { return this.size() > maxSize; } };1
2
3
4
5
6
7
# Properties 类
Hashtable 类的子类,可以用来读写配置文件(xml 文件、ini 文件、properties 文件)
key、value 都是 String 类型
修改 Properties 里的 key、value 值的方法:
Object setProperty(String key, String value):设置属性值,类似于 Hashtable 的put()方法String getProperty(String key):获取指定属性名对应的属性值,类似于 Map 的get(Object key)方法String getProperty(String key, String defaultValue):获取指定属性名对应的属性值,如果不存在指定的 key 时,则该方法返回指定默认值
读写属性文件的方法:
void load(InputStream inStream):从属性文件(以输入流表示)中加载 key-value 对,把加载到的 key-value 对追加到该 Properties 里void store(OutputStream out, String comments):将注释 comments 及该 Properties 中的 key-value 对输出到指定的属性文件(以输出流表示)中
获取当前工程路径:
System.getProperty("user.dir")
# TreeMap 类
- SortedMap 接口的实现类
- 底层采用红黑树来管理 key-value 对(红黑树的节点)
- TreeMap 存储 key-value 对(节点)时,需要根据 key 对节点进行排序(自然排序、定制排序)
- 保证 key 唯一的原理和 TreeSet 一样
# EnumMap
- EnumMap 是一个与枚举类一起使用的 Map 实现类,EnumMap 中的所有 key 都必须是同一个枚举类的枚举值(创建 EnumMap 时必须显式或隐式指定它对应的枚举类)
- 在内部以数组的形式保存,根据 key 的自然顺序(枚举值在枚举类的定义顺序)来维护 key-value 对的顺序
- 不允许使用 null 作为 key,但允许使用 null 作为 value

# 操作集合的工具类 Collections
java.util.Collections 中常用的类方法:
排序操作
void reverse(List list):反转指定 List 集合中元素的顺序
void shuffle(Listlist):对 List 集合元素进行随机排序
void sort(List list):根据元素的自然顺序对指定 List 集合的元素按升序进行排序(底层是调用 Arrays.sort())
sort(List<T> list, Comparator<? super T> c):根据指定比较器产生的顺序对指定 List 集合的元素进行排序
void swap(List list, int i, int j):将指定 List 集合的 i 处元素和 j 处元素进行交换查找、替换、添加操作
int binarySearch(List list, Object key):使用二分搜索法搜索指定对象在 List 集合中的索引(调用该方法时要求 List 中的元素已经处于有序状态)
Object min(Collection coll):根据元素的自然顺序, 返回给定集合中的最小元素
Object max(Collectioncoll):根据元素的自然顺序, 返回给定集合中的最大元素
boolean replaceAll(List list, Object oldVal, Object newVal):使用一个新值 newVal 替换 List 对象的所有旧值 oldVal
boolean addAll(Collection<? super T> c, T... elements):将所有指定元素添加到指定 collection 中创建空集对象
// 创建 List 空集对象 List<Object> list1 = Collections.EMPTY_LIST; // 返回的是不可变的空集合 List<Object> list2 = Collections.emptyList(); // 返回的是不可变的空集合 List<Object> list3 = new ArrayList<>(); // 从 jdk1.7 开始 ArrayList 的构造器默认创建的是空集1
2
3
4创建不可变的单元素集合
Set<T> singleton(T o):返回一个只包含指定对象的不可变 set
List<T> singletonList(T o):返回一个只包含指定对象的不可变列表
Map<K, V> singletonMap(K key, V value):返回一个不可变的映射,它只将指定键映射到指定值返回不可修改的集合视图
List<T> unmodifiableList(List<T> list):返回指定列表的不可修改视图Set<T> unmodifiableSet(Set<T> s):返回指定 set 的不可修改视图Map<K, V> unmodifiableMap(Map<K, V> m):返回指定映射的不可修改视图同步控制:将集合对象包装成线程同步的集合
// 创建线程安全的集合对象 List<Object> list = Collections.synchronizedList(new ArrayList<>()); Set<Object> set = Collections.synchronizedSet(new HashSet<>()); Map<String, Object> map = Collections.synchronizedMap(new HashMap<>()); // 在返回的集合对象上进行迭代时,需要手动同步 synchronized (list) { Iterator it = list.iterator(); while (it.hasNext()) it.next(); }1
2
3
4
5
6
7
8
9
10
11从 Map 创建 Set
Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));1