Java Virtual Machine Technology (opens new window)
- 编译器负责生成字节码
- JIT 编译器负责优化成本地代码
- JVM 解释器负责输出期望结果
- 字节码优化技术:内联 inlining、消除 elimination、标量化 scalarization
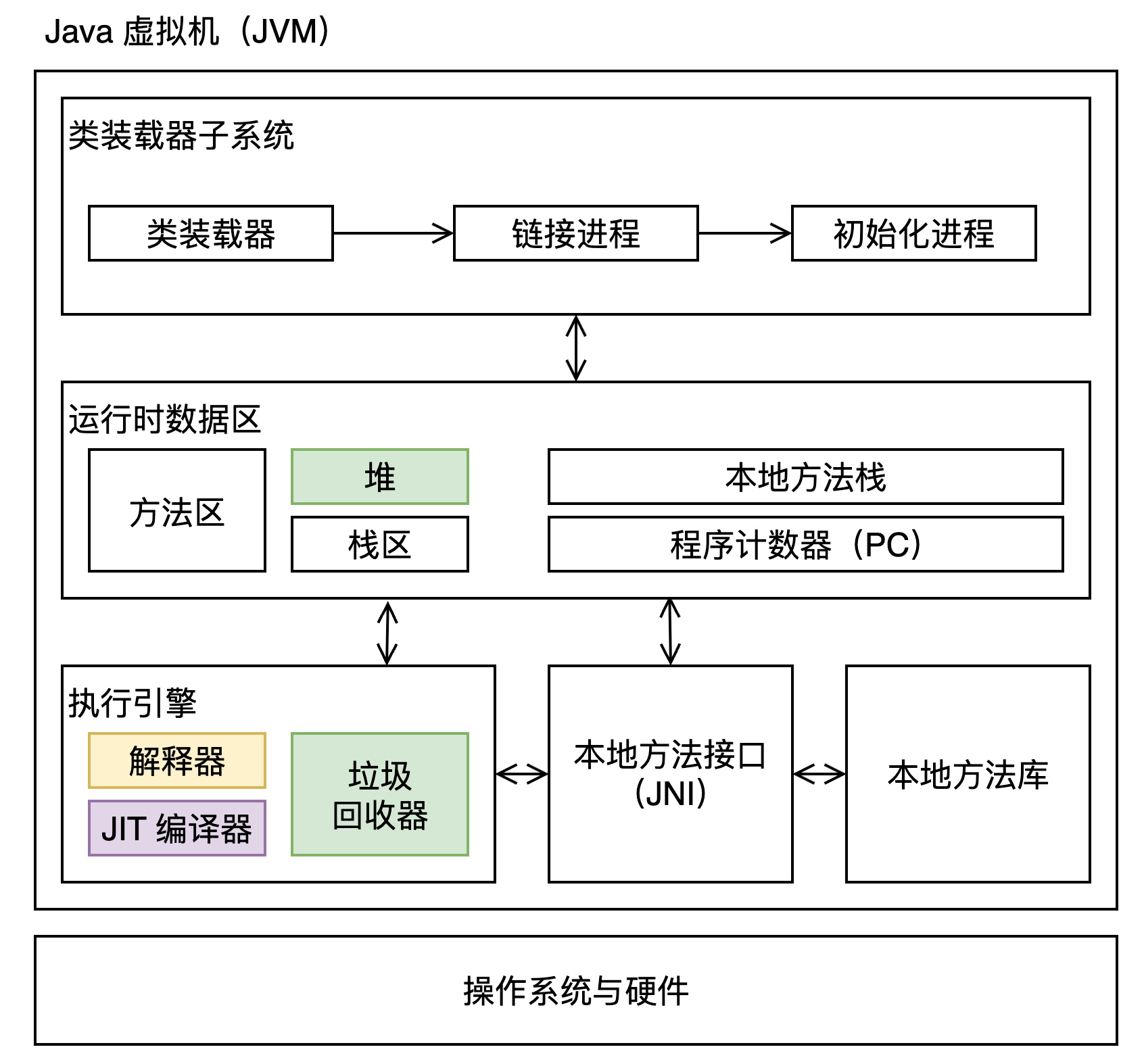
# JVM 内存结构
虚拟机在执行 Java 程序的过程中会把所管理的内存划分为若干个不同的数据区域:
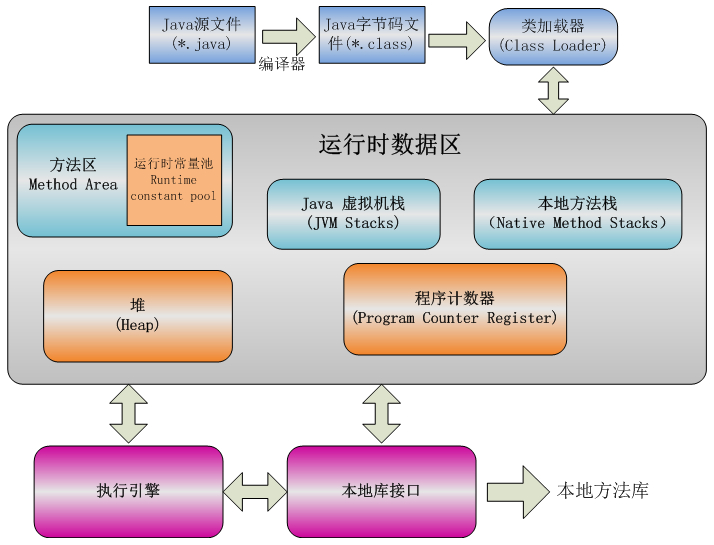
- 方法区:与堆一样,是各个线程共享的内存区域,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
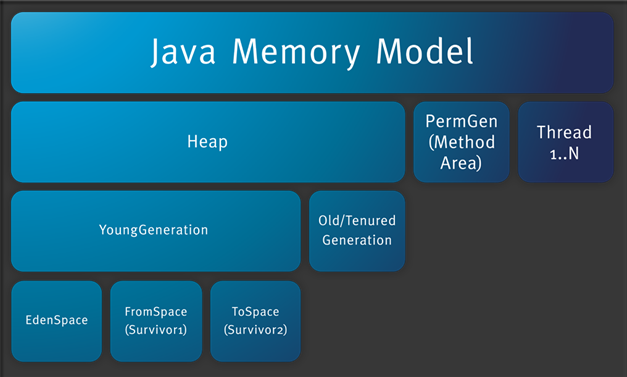
- HotSpot 虚拟机把方法区叫做永久代(Permanent Generation)
- 在 jdk1.7 中,符号引用放到 native heap,字符串常量、类的静态变量放到 java heap
- 在 jdk1.8 中,永久代被移除,类的元数据放到本地堆内存(native heap)中,这一块区域叫 Metaspace(元空间)
- 运行时常量池:方法区的一部分,用于存放编译器生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中
- 堆:被所有线程共享的一块内存区域,在虚拟机启动时创建。所有的对象实例以及数组都要在堆上分配内存
- 使用 new 关键字,就表示在堆中开辟一块新的存储空间
- 堆内存又被划分成不同的部分:伊甸区(Eden)、幸存者区域(Survivor Space)、老年代(Old Generation Space)
- 堆内存由新生代/年轻代和老年代组成,而新生代又被分成三部分,Eden 空间、From Survivor 空间、To Survivor 空间,默认情况下新生代按照 8:1:1 的比例来分配
- 伊甸区(Eden),对象被创建的时候首先放到这个区域,进行垃圾回收后,不能被回收的对象被放入到空的 To Survivor 空间
- Java 虚拟机栈:每个线程在创建时都会创建一个虚拟机栈,其内部保存一个个的栈帧,每个方法被执行时都会同时创建一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息;当方法调用完毕,该方法的栈帧就被销毁了
- 本地方法栈:每个线程在调用本地方法时都会创建一个栈帧,为虚拟机使用到的 native 方法服务
- 程序计数器:每个线程都有自己的程序计数器,用来记录当前线程正在执行的字节码指令的地址
# JVM 常见参数
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
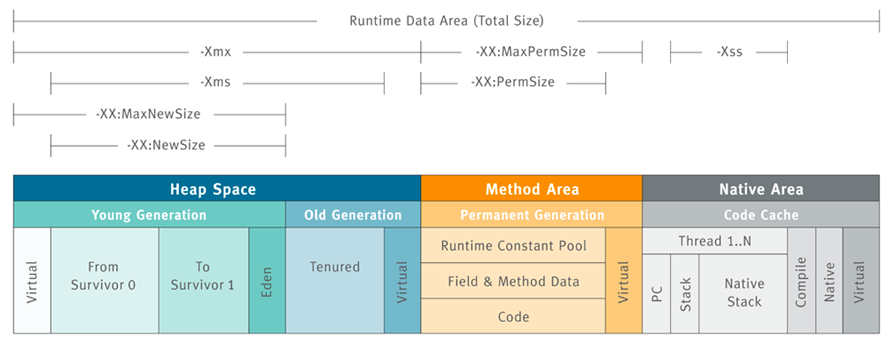
- -Xms
或 -XX:InitialHeapSize设置堆的初始空间大小,默认为物理内存的 1/64,默认单位为 字节,可用单位:k 或 K、m 或 M、g 或 G - -Xmx
或 -XX:MaxHeapSize设置堆的最大空间大小,默认为物理内存的 1/4 - -Xss
或 -XX:ThreadStackSize设置每个线程的栈大小,jdk1.5 以后默认为 1M - -Xdebug 在调试模式下运行
- -Xmn 设置新生代初始空间和最大空间大小
- -XX:NewSize 设置新生代初始空间大小
- -XX:MaxNewSize 设置新生代最大空间大小
-XX:PermSize 设置永久代初始空间大小-XX:MaxPermSize 设置永久代最大空间大小- -XX:MetaspaceSize 设置元空间初始空间大小
- -XX:MaxMetaspaceSize 设置元空间最大空间大小
- -XX:NewRatio 设置老年代与新生代的比值,默认值为 2(新生代占 1,老年代占2,即新生代占整个堆的 1/3)
- -XX:SurvivorRatio 设置新生代中 Eden 区与 2 个 Survivor 区的比值
- -XX:MaxTenuringThreshold 表示一个对象如果在 Survivor 区移动的次数达到设置值还没有被垃圾回收就进入老年代(如果设置为 0,则新生代对象不经过 Survivor 区,直接进入老年代)(The default value is 15 for the parallel (throughput) collector, and 6 for the CMS collector.)
- -XX:PretenureSizeThreshold 直接晋升到老年代的对象大小,默认为 0
- -XX:+PrintCommandLineFlags 输出 JVM 的启动参数
- -XX:+PrintGC 输出 GC 日志
- -XX:+PrintGCDetails 输出详细的 GC 处理日志
- -XX:+PrintGCDateStamps 输出 GC 发生时的日期戳
- -XX:+PrintGCTimeStamps 输出 GC 发生时 JVM 的启动时间
- -XX:+PrintHeapAtGC 输出 GC 前后的堆内存情况
- -XX:+PrintGCApplicationStoppedTime 输出应用由于 GC 而产生的停顿时间
- -Xloggc:gc.log 输出 GC 日志到文件
- -XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1 输出 safepoint 信息,日志会输出到 JVM 进程的标准输出(GC 调试)
- -XX:+HeapDumpOnOutOfMemoryError 当 JVM 出现 OOM 时生成一个 HPROF 格式的堆转储文件(默认文件名
java_pid<进程号>.hprof) - -XX:HeapDumpPath=/home/app/jvmheap
http://jvmmemory.com/
最大线程数量 =(机器本身可用内存 - JVM 分配的堆内存)/ Xss 值
为了减少 JVM 垃圾回收和重新分配内存的频率可以把 Xms 和 Xmx 设置同样的值
-Xmx2g XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=. -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -XX:+PrintGCApplicationStoppedTime -Xloggc:gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M
注意设置 JVM 参数(VM options)的方式:
java [-options] -jar jarfile [args...]打印 VM 参数:
ManagementFactory.getRuntimeMXBean().getInputArguments();记录 Java GC 日志: 对于 Java 4、5、6、7、8,
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<file-path>;对于 Java 9,-Xlog:gc*:file=<file-path>
# GC 算法
# 对象存活判断
判断对象是否存活一般有两种方式:
- 引用计数:每个对象有一个引用计数属性,新增一个引用时计数加 1,引用释放时计数减 1,计数为 0 时可以回收(Java 并没有选择引用计数,因为存在对象相互循环引用的问题)
- 可达性分析(Reachability Analysis):从 GC Roots 开始向下搜索,搜索所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连时,则认为此对象是不可达的
可作为 GC Roots 的对象包括以下几种:
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,例如各个线程被调用的方法堆栈中使用到的参数、局部变量、临时变量等
- 在本地方法栈中 JNI(即通常所说的 Native 方法)引用的对象
- 在方法区中类静态属性引用的对象,例如 Java 类的引用类型静态变量
- 在方法区中常量引用的对象,例如字符串常量池里的引用
- 被同步锁(synchronized 关键字)持有的对象
- JVM 内部的引用,如基本数据类型对应的 Class 对象,系统类加载器、一些常驻的异常对象(比如 NullPointerException、OutOfMemoryError)等
- 反映 JVM 内部情况的 JMXBean、JVMTI 中注册的回调、本地代码缓存等
Types of GC roots (opens new window)
- JNI global reference
- JNI local reference
- Local variable on stack - 本地方法栈中的局部变量。这些变量通常存在于栈中,引用对象则存在于堆中。
- Monitor - 用作同步监视器的对象。
- System class - 由启动类加载器(Bootstrap ClassLoader)加载的类。这些类通常是 Java 标准库的一部分,并在 JVM 启动时加载。
- Thread - 活动的 Java 线程(已启动但未停止的线程)。运行中的线程无法被收集。线程对象及其堆栈可以通过其线程局部变量保存对其它对象的引用。
- Other - JVM 出于其目的而从垃圾收集中保留的对象(与 JVM 的实现有关)。可能的已知情况有:系统类加载器、一些 JVM 知道的重要的异常类、一些用于处理异常的预分配对象、以及在加载类的过程中的自定义类加载器等。
Implementing Finalization (opens new window)
A reachable object is any object that can be accessed in any potential continuing computation from any live thread.
Optimizing transformations of a program can be designed that reduce the number of objects that are reachable to be less than those which would naively be considered reachable. For example, a Java compiler or code generator may choose to set a variable or parameter that will no longer be used to null to cause the storage for such an object to be potentially reclaimable sooner.
可达对象(reachable object)是可以从任何活动线程的任何潜在的持续访问中的任何对象。java 编译器或代码生成器可能会对不再访问的对象提前置为 null,使得对象可以被提前回收。
class A {
@Override protected void finalize() {
System.out.println(this + " was finalized!");
}
public static void main(String[] args) throws InterruptedException {
A a = new A();
System.out.println("Created " + a);
for (int i = 0; i < 1_000_000_000; i++) {
if (i % 1_000_00 == 0)
System.gc();
}
System.out.println("done.");
}
}
// 打印结果
// 方法没有执行完,栈帧并没有出栈,但是对象 a 被提前回收
Created A@1be6f5c3
A@1be6f5c3 was finalized! //finalize 方法输出
done.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 垃圾回收机制
- 自动垃圾回收机制;只能回收堆内存中不再被程序引用的对象所占的内存
- 回收内容:堆中的可回收对象;方法区无用的元数据(卸载不再使用的类型,默认 -XX:+ClassUnloadingWithConcurrentMark)
# 引用类型
- 强引用(Strong Reference):默认,最常见的一种,只要该引用存在,就不会被 GC
- 软引用(Soft Reference):SoftReference,内存空间不足时才会被回收,使用场景:实现内存敏感的缓存(如:缓存图片、大文本、计算结果等)
- 弱引用(Weak Reference):WeakReference,下次 GC 时无论内存是否充足都会被回收,使用场景:临时性缓存或监听器列表
- 虚引用(Phantom Reference):PhantomReference,不会对其生存时间构成影响,其 PhantomReference#get() 方法总是返回 null,因此无法获取被引用的对象,主要用于跟踪一个对象被回收的过程
# 垃圾收集算法
- 垃圾收集算法主要有:复制、标记-清除、标记-整理
| 算法名称 | 核心过程 | 主要优点 | 主要缺点 | 典型应用区域 |
|---|---|---|---|---|
| 复制 | 将存活对象从“From”区复制到“To”区 → 清空“From”区 | 效率高,无内存碎片 | 浪费一半内存空间 | 新生代的 Eden 和 Survivor 区 |
| 标记-清除 | 标记存活对象 → 清除未标记对象 | 实现简单 | 产生内存碎片,分配大对象时效率低 | CMS 收集器的老年代 |
| 标记-整理 | 标记存活对象 → 向一端移动 → 清理边界 | 无内存碎片 | 移动对象有开销,速度相对较慢 | Serial Old、Parallel Old 收集器的老年代 |
| 分代收集 | 根据对象生命周期将堆分为新生代和老年代,对不同代采用上述最合适的算法 | 综合效率高,是现代 JVM 的基石 | 算法本身较复杂 | 整个 Java 堆 |
复制算法(Copying)
- 将内存分为大小相等的两块,每次只用其中一块,一块内存用完之后,将存活对象复制到另一块内存区域,然后将原来的半块内存区域全部回收
- 只需移动堆顶指针,按顺序分配内存即可,实现简单,运行高效,且内存回收后不会产生内存碎片
- 缺点:可用内存缩小为原来的一半,代价高
标记-清除算法(Mark-Sweep)
- 标记所有存活对象,然后统一回收未被标记的对象
- 缺点:标记和清除过程的效率都不高;内存回收后会产生大量不连续的内存碎片
标记-整理算法(Mark-Compact)
- 标记所有存活对象,将存活对象移动到内存的一端,然后将端边界以外的内存回收
- 避免了内存碎片问题,但代价是对象移动带来的开销,速度相对较慢
分代收集算法(Generational Collection)
- GC 分代的基本假设:绝大部分对象的生命周期都非常短暂,存活时间短
- 把 Java 堆分为新生代和老年代,根据各个年代的特点采用最适当的收集算法
- 在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集;而老年代中因为对象存活率高、没有额外空间对它进行分配担保,必须使用“标记-清理”或“标记-整理”算法来进行回收
# 垃圾收集过程
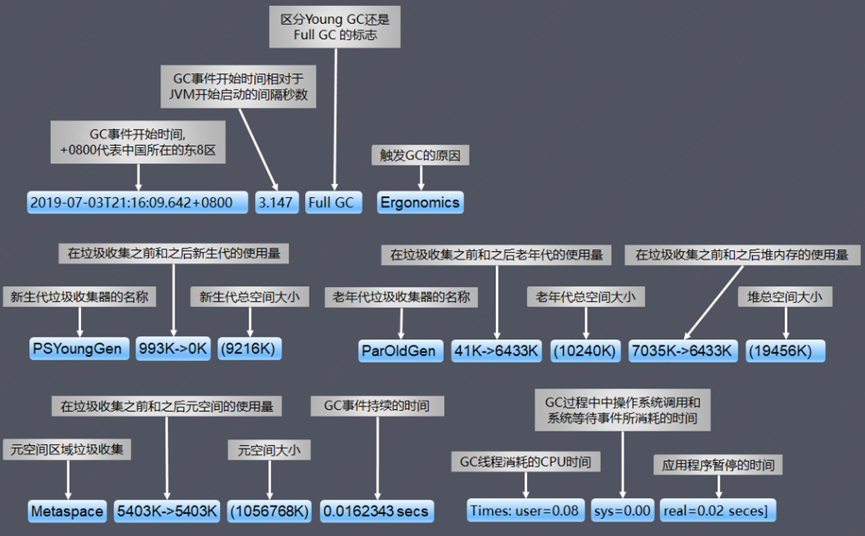
当 Eden 区空间不足、无法为新对象分配内存时,触发 Minor GC(又称 Young GC):
- Eden 区中所有存活的对象都会被复制到 To 区域
- 在 From 区域中仍存活的对象会根据它们的年龄值来决定去向,年龄达到一定值(年龄阈值)的对象会被移动到老年代中,没有达到阈值的对象会被复制到 To 区域
- 清空 Eden 区和 From 区,然后 From 区和 To 区的角色互换
Major GC/Old GC:指目标只是老年代的垃圾收集,目前只有 CMS 收集器会有单独收集老年代的行为
对整个堆和元空间进行的清理叫作 Full GC,触发条件:手动调用
System.gc()、老年代或元空间空间不足- 年轻代全部对象大小 > 老年代剩余空间
- 从年轻代存活超过 15 次后进入老年代的对象大小 > 老年代剩余空间
- Survivor 区中不足以容纳年轻代中存活下来的对象,此时这部分的对象大小 > 老年代剩余空间
- 如果是 CMS 收集器,老年代剩余空间 < 参数比例
# 垃圾收集器 Garbage Collector
Java HotSpot Virtual Machine Garbage Collection Tuning Guide (opens new window)
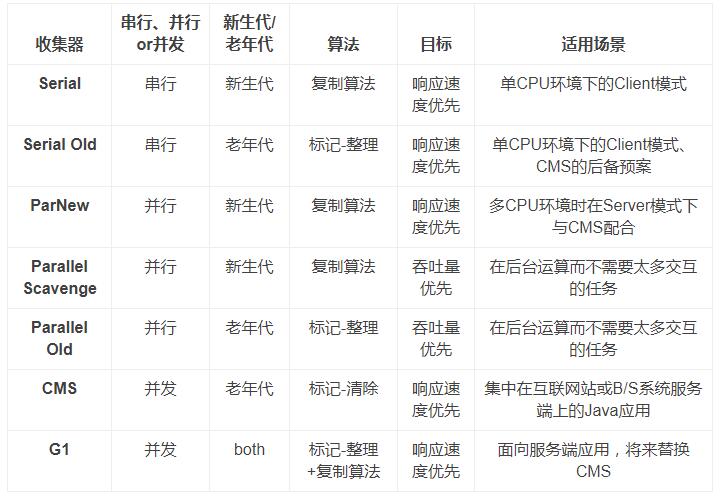
- Serial 收集器:一个采用单个线程并基于复制算法工作在新生代的收集器,进行垃圾收集时,必须暂停其它所有的工作线程(Stop The World),是 Client 模式下 JVM 的默认选项,-XX:+UseSerialGC
- ParNew 收集器:Serial 收集器的多线程版本(使用多个线程进行垃圾收集),-XX:+UseParNewGC,是启用 CMS 收集器时新生代的默认收集器
- Parallel Scavenge 收集器:一个采用多线程基于复制算法并工作在新生代的收集器,也被称作是吞吐量优先的 GC,是早期 jdk1.8 等版本中 Server 模式 JVM 的默认 GC 选择,-XX:+UseParallelGC,使用 Parallel Scavenge(新生代)+ Serial Old(老年代)的组合进行 GC
- Serial Old 收集器:一个采用单线程基于标记-整理算法并工作在老年代的收集器
- CMS 收集器(Concurrent Mark Sweep):一种以尽量减少停顿时间为目标的收集器,工作在老年代,基于标记-清除算法实现,-XX:+UseConcMarkSweepGC,CMS 的执行过程可以分为以下几个阶段:初始标记(STW)→并发标记→并发预清理→重标记(STW)→并发清理→重置
- Parallel Old 收集器:一个采用多线程基于标记-整理算法并工作在老年代的收集器,适用于注重于吞吐量及 CPU 资源敏感的场合,-XX:+UseParallelOldGC,使用 Parallel Scavenge(新生代)+ Parallel Old(老年代)的组合进行 GC
- G1 收集器(Garbage-First):jdk1.7 提供的一个工作在新生代和老年代的收集器,基于标记-整理算法实现,在收集结束后可以避免内存碎片问题,一种兼顾吞吐量和停顿时间的 GC,适用于大内存堆(如超过 4GB)和对响应速度有一定要求的应用,是 Oracle JDK 9 以后的默认 GC 选项
- 将堆内存划分为多个大小固定的 Region
- 每个 Region 可以被动态指定为 Eden、Survivor、Old 或特殊的 Humongous Region(存放大对象)
- 优先回收垃圾最多的 Region,从而在有限的时间内尽可能释放更多的内存
- 整体基于 标记-整理,局部(两个 Region 间)基于 标记-复制
- Young GC 和 Mixed GC,对 Region 的处理过程:标识 Region 内的存活对象,将存活对象复制到新的空闲 Region 中(例如,年轻代对象复制到 Survivor Region,老年代对象复制到其他 Old Region),清空原 Region
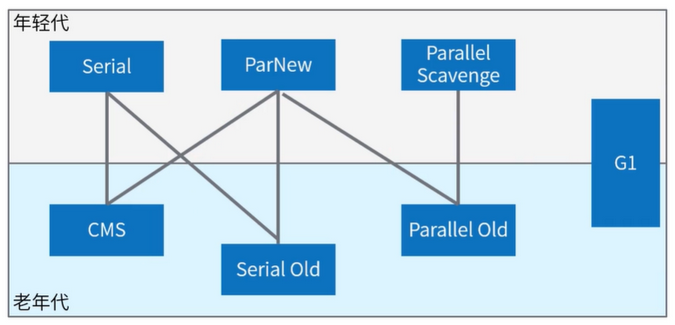
- jdk1.7、jdk1.8 默认垃圾收集器 Parallel GC,即 Parallel Scavenge(新生代)+ Parallel Old(老年代)
- jdk1.9 - jdk18 默认垃圾收集器 G1
java -XX:+PrintCommandLineFlags -version 查看 JVM 使用的 XX 选项的默认值
JDK-6679764 : enable parallel compaction by default (opens new window):在 jdk7u4 之前 -XX:+UserParallelGC 使用的是 Parallel Scavenge + Serial Old,在这个版本后 Parallel Old GC 已经很成熟了,所以直接替换了旧的收集器,所以 jdk7u4 后的 JDK7 和 JDK8 默认使用的都是 Parallel Scavenge + Parallel Old
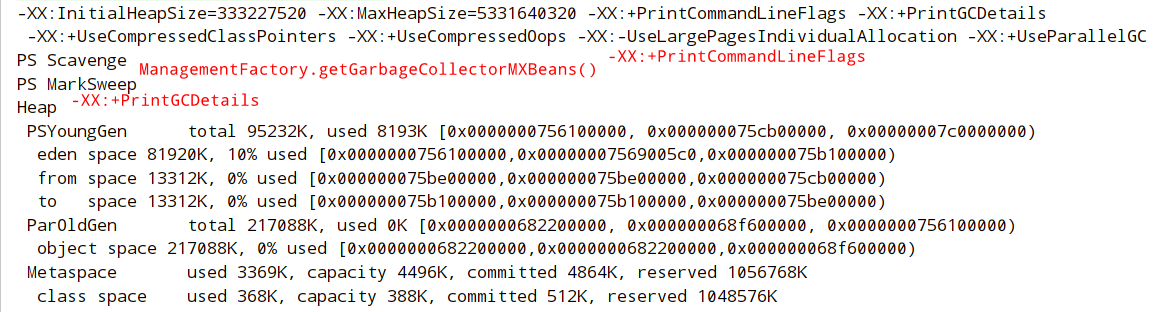
GC 线程数
- GC 默认线程数与 JVM 检测到的可用 CPU 核心数有关
- 容器化环境,强烈建议显式设置 -XX:ParallelGCThreads 和 -XX:ConcGCThreads,或设置 -XX:ActiveProcessorCount(指定可用处理器数量,JDK8 后期版本可用,验证方法
Runtime.getRuntime().availableProcessors()) - 原因:JVM 默认读取 /proc/cpuinfo 获取核心数,这通常是宿主机的核心数,远大于容器实际分配到的 CPU 资源。导致默认 GC 线程数过多,引发严重的 CPU 资源竞争和性能下降。
GC 调优思路:明确目标 -> 收集数据 -> 分析问题 -> 调整验证 -> 持续监控
- 降低 GC 频率:可以通过增大堆空间,减少不必要对象生成
- 降低 GC 暂停时间:可以通过减少堆空间,使用 CMS GC 算法实现
- 避免 Full GC:调整 CMS 触发比例,避免 Promotion Failure 和 Concurrent mode failure(老年代分配更多空间,增加 GC 线程数加快回收速度),减少大对象生成等
# 内存溢出和内存泄漏
内存溢出(OutOfMemoryError):内存溢出指的是程序请求的内存超出了 JVM 当前允许的最大内存容量。当 JVM 试图为一个对象分配内存时,如果当前可用的堆内存不足以满足需求,就会抛出 java.lang.OutOfMemoryError 异常。这通常是因为堆空间太小或者由于某些原因导致堆空间被占满。
内存泄漏(Memory Leak):内存泄漏是指不再使用的内存空间没有被释放,导致这部分内存无法再次被使用。虽然内存泄漏不会立即导致程序崩溃,但它会逐渐消耗可用内存,最终可能导致内存溢出。
区别:虽然都与内存相关,但它们发生的时机和影响有所不同。内存溢出通常发生在程序运行时,当数据结构的大小超过预设限制时,常见的情况是需要分配一个大对象,比如一次从数据中查到了过多的数据。而内存泄漏和“过多”关系不大,是一个细水长流的过程,一次内存泄漏的影响可能微乎其微,但随着时间推移,多次内存泄漏累积起来,最终可能导致内存溢出。
# JVM 性能监控与故障诊断工具
JDK Tools and Utilities (opens new window)
# JDK 监控和故障诊断命令行工具
- jps -l:JVM 进程状态工具,列出系统上的 JVM 进程(-l 表示输出主类的全名)
- jcmd:JVM 命令行调试工具,用于向 JVM 进程发送调试命令
- jstat:JVM 统计监控工具,附加到一个 JVM 进程上收集和记录 JVM 的各种性能指标数据
jstat -gcutil <pid> 5s 10:输出 GC 和内存占用汇总信息,每隔 5 秒输出一次,输出 10 次(其中,S0 表示 Survivor0 区占用百分比,S1 表示 Survivor1 区占用百分比,E 表示 Eden 区占用百分比,O 表示老年代占用百分比,M 表示元数据区占用百分比,YGC 表示新生代回收次数,YGCT 表示新生代回收耗时,FGC 表示老年代回收次数,FGCT 表示老年代回收耗时)
- jstack:JVM 栈查看工具,可以打印 JVM 进程的线程栈和锁情况
- jinfo:JVM 信息查看工具,查看 JVM 的各种配置信息
- jmap:JVM 堆内存分析工具,可以打印 VM 进程对象直方图、类加载统计,以及做堆转储操作
jmap -dump:format=b,file=/tmp/a.hprof <pid>:生成虚拟机的堆内存转储快照(heapdump 文件)jmap -heap <pid>:显示堆详细信息,包括使用的 GC 算法、堆配置信息和各内存区域内存使用信息jmap -histo:live <pid>:显示堆中对象的统计信息,包括每个 Java 类的对象数量(只计算活动的对象)、内存大小
- jhat:JVM Heap Dump Browser,用于分析 heapdump 文件,它会建立一个 HTTP/HTML 服务器,让用户可以在浏览器上查看分析结果
# 定位问题线程信息
jps # 查看 Java 进程的进程 id(21711)
top -Hp 21711 # 查看进程的线程信息
# 输入 P 将线程按照 CPU 使用率排序
printf "%x\n" 21742 # 21742 对应的 16 进制值,为 54ee
jstack 21711 | grep 54ee -A100 > dump.log # 查看线程快照(注意:执行该命令的用户需是该进程的运行用户)
# 使用 python 开启一个简单 http 服务
python3 -m http.server 8080
curl -o http://ip地址:8080/dump.log
2
3
4
5
6
7
8
9
- 线程快照中线程状态有:
- 死锁,Deadlock(重点关注)
- 执行中,Runnable
- 等待资源,Waiting on condition(重点关注)
- 等待获取监视器,Waiting on monitor entry(重点关注)
- 暂停,Suspended
- 对象等待中,Object.wait() 或 TIMED_WAITING
- 阻塞,Blocked(重点关注)
- 停止,Parked
- 在线分析工具:fastThread (opens new window)(Java Thread Dump Analyzer)、GCeasy (opens new window)(Universal GC Log Analyzer)、HeapHero (opens new window)(Java Heap Dump Analyzer)
# JDK 中的可视化工具
- jvisualvm:综合的 JVM 监控工具,查看 JVM 基本情况、做栈和堆转储、做内存和 CPU profiling 等(可安装 Visual GC 插件)
- jconsole:JMX 兼容的图形工具,用于监控 JVM 基本情况,查看 MBean
- jmc(Java Mission Control)
# 其它监控分析工具
- MAT (opens new window)(Memory Analyze Tool),introduction (opens new window)
- JProfiler (opens new window)
- Async-profiler (opens new window):Java 采样分析器,使用 HotSpot 特有的 API 来收集堆栈跟踪并跟踪内存分配
- jattach (opens new window):JVM 动态连接工具,集成了 jmap + jstack + jcmd + jinfo 功能,无需安装 JDK,只需使用 JRE 即可运行,支持 Linux 容器
- Arthas (opens new window)(阿尔萨斯):Java 诊断工具
使用 MAT 分析 OOM 问题,一般可以按照以下思路进行:
- 通过支配树功能或直方图功能查看消耗内存最大的类型,来分析内存泄露的大概原因
- 查看那些消耗内存最大的类型、详细的对象明细列表,以及它们的引用链,来定位内存泄露的具体点
- 配合查看对象属性的功能,可以脱离源码看到对象的各种属性的值和依赖关系,帮助我们理清程序逻辑和参数
- 辅助使用查看线程栈来看 OOM 问题是否和过多线程有关,甚至可以在线程栈看到 OOM 最后一刻出现异常的线程
# Java 内存模型(JMM)
Java 内存模型(Java Memory Model,JMM)是 Java 虚拟机规范中所定义的一种内存模型,定义了多线程环境下程序中各个共享变量的访问规则。
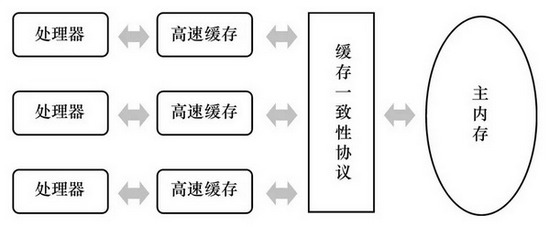
- 每个 CPU 都有自己的高速缓存,所有 CPU 共享同一个主内存
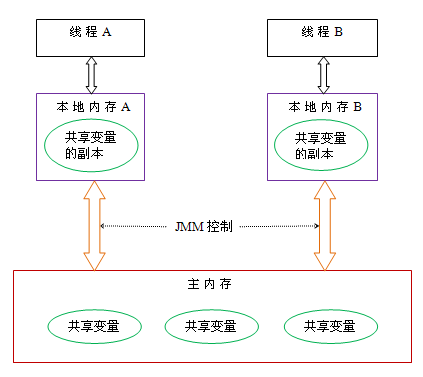
- 所有的共享变量都存储在主内存(Main Memory)中
- 每个线程有自己的工作内存(Working Memory),线程的工作内存中保存了该线程使用到的变量的主内存的副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(volatile 变量仍然有工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如同直接在主内存中读写访问一般)
- 不同的线程之间也无法直接访问对方工作内存中的变量,线程之间值的传递都需要通过主内存来完成
对于非 volatile 变量,其工作内存与主内存的同步时机是不确定的,主要依赖 synchronized 块的进入和退出、线程结束以及上下文切换等时机
# Java 对象模型
- Java 对象在 JVM 中的存储结构/数据结构
- HotSpot 虚拟机中,设计了一个 OOP-Klass Model,OOP(Ordinary Object Pointer)指的是普通对象指针,而 Klass 用来描述对象实例的具体类型
- 每一个 Java 类,在被 JVM 加载的时候,JVM 会给这个类创建一个 instanceKlass,保存在方法区,用来在 JVM 层表示该 Java 类
- 当在 Java 代码中使用 new 创建一个对象的时候,JVM 会创建一个 instanceOopDesc 对象,这个对象中包含了对象头以及实例数据
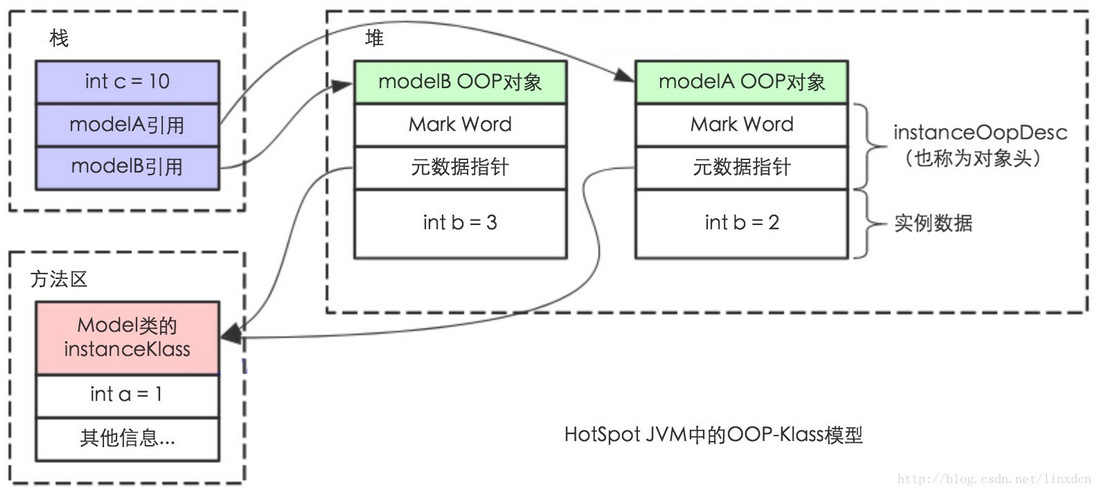
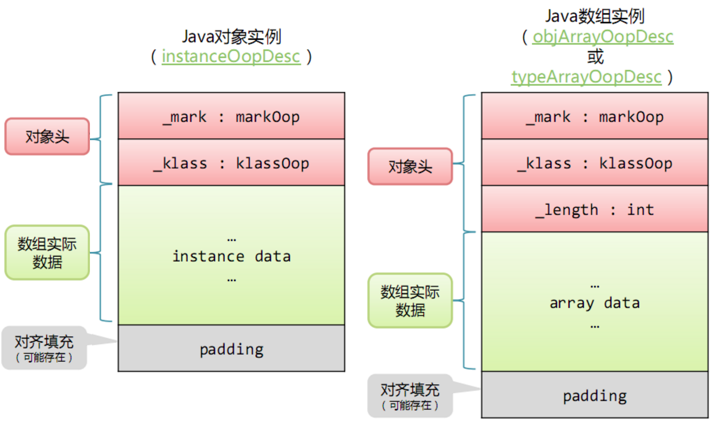
- 在 HotSpot 虚拟机中,Java 对象在内存中存储的布局可以分为 3 块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)
- 对象头
- Mark Word,用于存储对象自身的运行时数据,如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等,其中的最后 2bit 是锁状态标志位(无锁、偏向锁、轻量级锁、重量级锁、GC 标识)
- 类型指针(元数据指针),即对象指向它的类元数据的指针,JVM 通过该指针来确定这个对象是哪个类的实例
- 数组长度,如果对象是一个数组,在对象头中还有一块数据用于记录数组长度
- 实例数据
- 实例数据部分是对象真正存储的有效信息,也是在程序代码中所定义的各种类型的字段内容。无论是从父类继承下来的,还是在子类中定义的,都需要记录起来。
- 类变量所占用的空间通常不算在对象本身,因为其引用是在方法区
- 基本类型所占内存大小:byte(1b)、short(2b)、int(4b)、long(8b)、float(4b)、double(8b)、char(2b)、boolean(1b)
- 对齐填充
- 由于 HotSpot JVM 的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,即对象的大小必须是 8b 的整数倍,当对象的对象头+实例数据不是 8 的倍数时,需要通过对齐填充来补全
- Java 对象所占内存大小
- 一般非数组对象:12b 对象头(8b Mark Word + 4/8b 元数据指针)+ 数据区 + padding 内存对齐(按照 8 的倍数对齐)
- 数组对象:16/20b 对象头(8b Mark Word + 4/8b 元数据指针 + 4b 数组长度)+ 数据区 + padding 内存对齐(按照 8 的倍数对齐)
- Oracle JDK 从 6 update 23 开始在 64 位系统、堆内存小于 32GB 的情况下会默认开启压缩指针
UseCompressedOops,将原来 64 位的指针压缩为 32 位,即此时指针为 4b
- 获取对象所占内存字节数:
ObjectSizeCalculator.getObjectSize(obj)